← 首页
Internal Sharing · 技术分享
AI 编程分享
01 · Mindset
先别学工具,先转变思维方式
1.1 AI 编程的进化史
从 IDE 智能提示,到 Copilot 行内补全,到 Chat 式问答,再到今天的 Code Agent——AI 在工程师工作流里的位置越来越靠近"决策端",而不只是"执行端"。每一代的飞跃都不是"补全更准",而是 AI 主动承担的范围更大:从一个词、一行、一段,到整个任务。
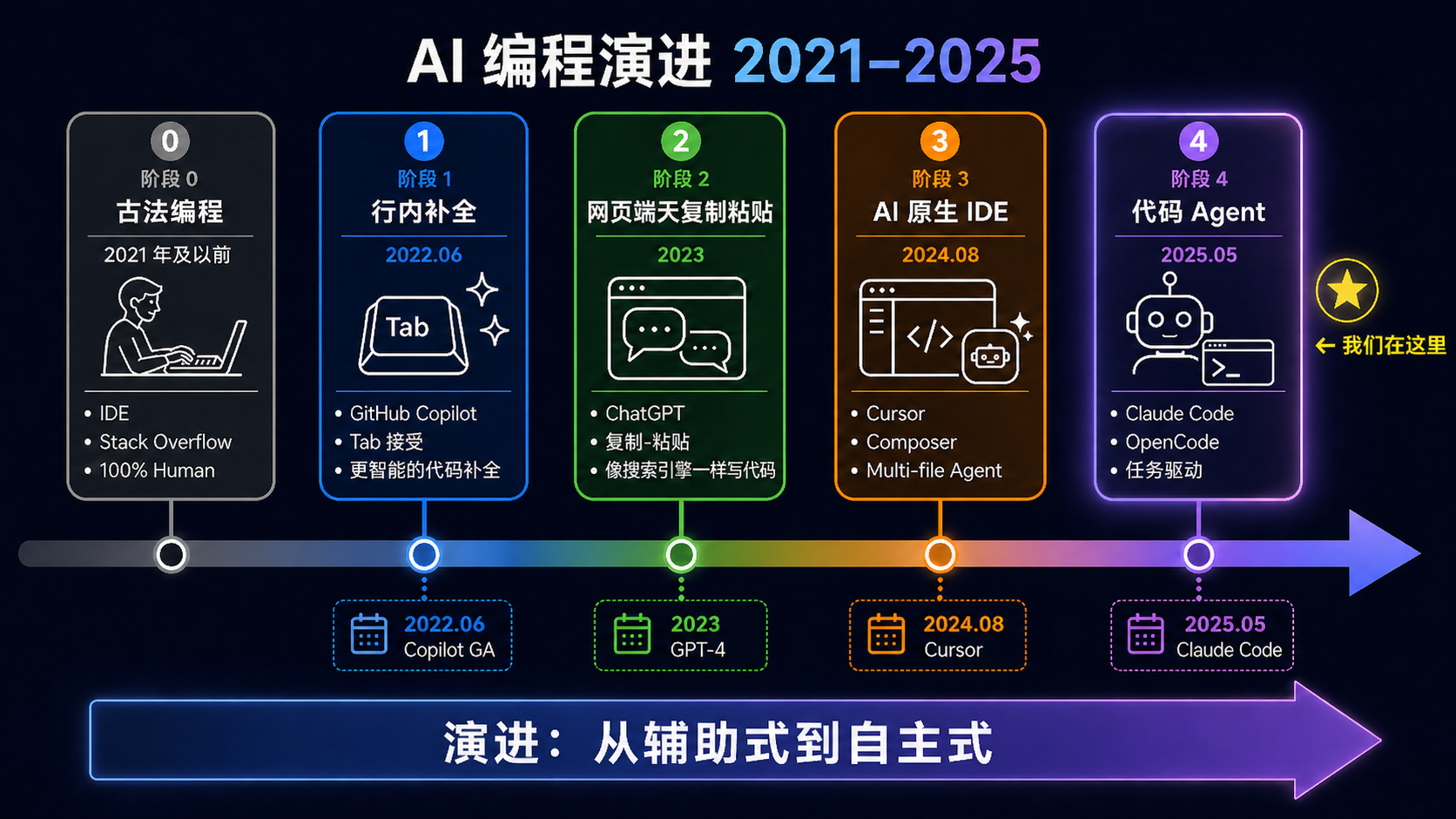 图 1.1 · AI 编程工具的四代演进
图 1.1 · AI 编程工具的四代演进
1.2 思维转变:从"问 AI"到"派 AI"
走到第 4 阶段(Code Agent)之后,你的角色变了。
过去你是写代码的人,AI 是辅助工具;现在 AI 是干活的人,你是派活、定边界、审产出的"项目经理"。这不是修辞——它是工作方式的彻底重组。
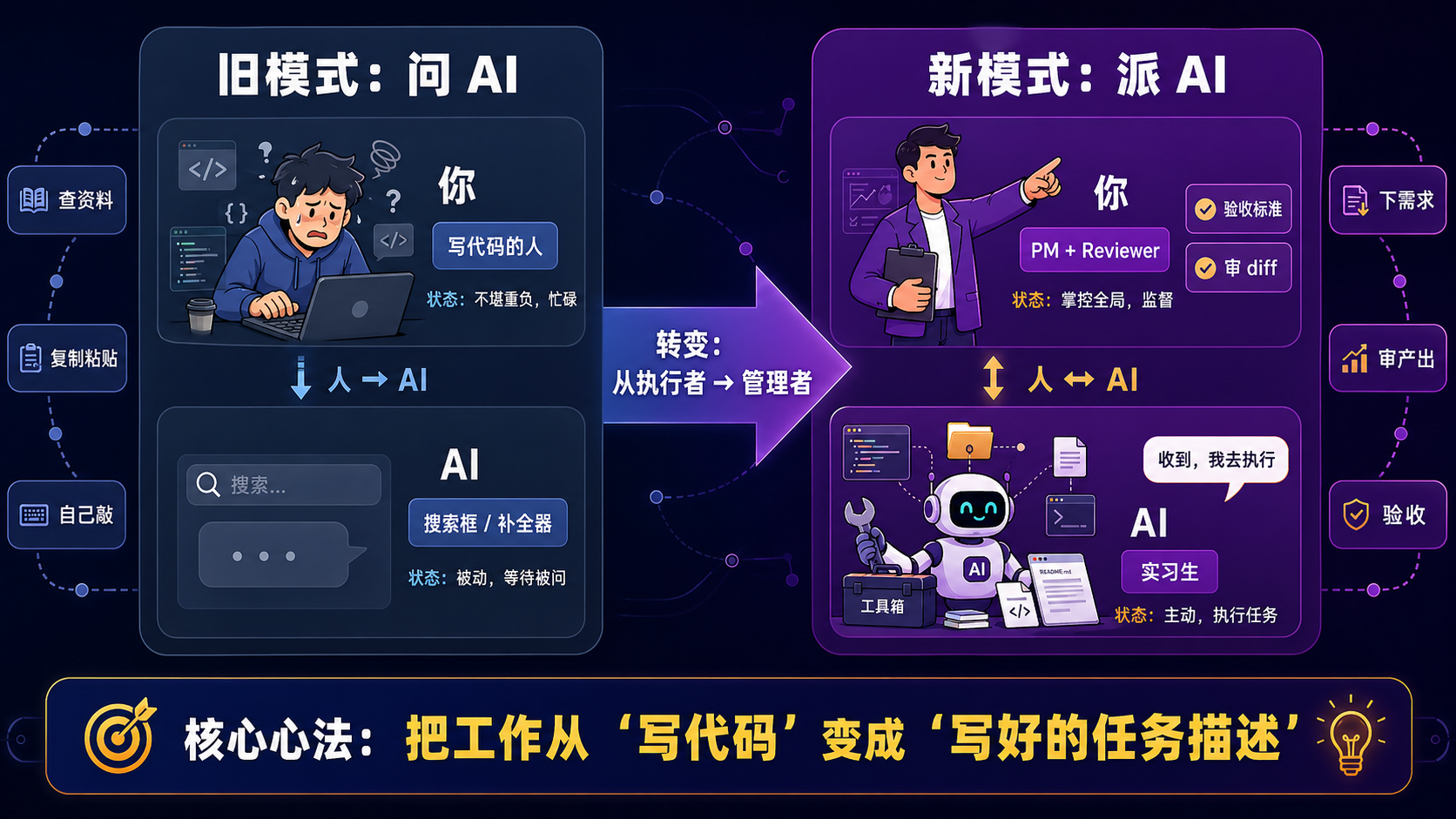 图 1.2 · 从"自己写"到"派 AI 写"的工作模式切换
图 1.2 · 从"自己写"到"派 AI 写"的工作模式切换
本章 Takeaway
在学任何工具的具体操作之前,先把自己定位在"派活的人"。后面所有章节——AGENTS.md、Plan 先行、Context 工程、Skills 体系——本质上都是为这一个角色服务的。
02 · Getting Started
上手 OpenCode
2.1 先认识 OpenCode:一次会话长什么样
很多人第一次启动 OpenCode 会愣一下:"咦?怎么是终端里的东西?我的 IDE 呢?"
这很正常。Code Agent 这一代工具刻意选择"住在终端",不绑定任何 IDE——因为它不是来"补全你的代码"的,它是来"替你完成任务"的。它需要直接调用 shell、跑命令、读写文件,终端是最自然的栖息地。
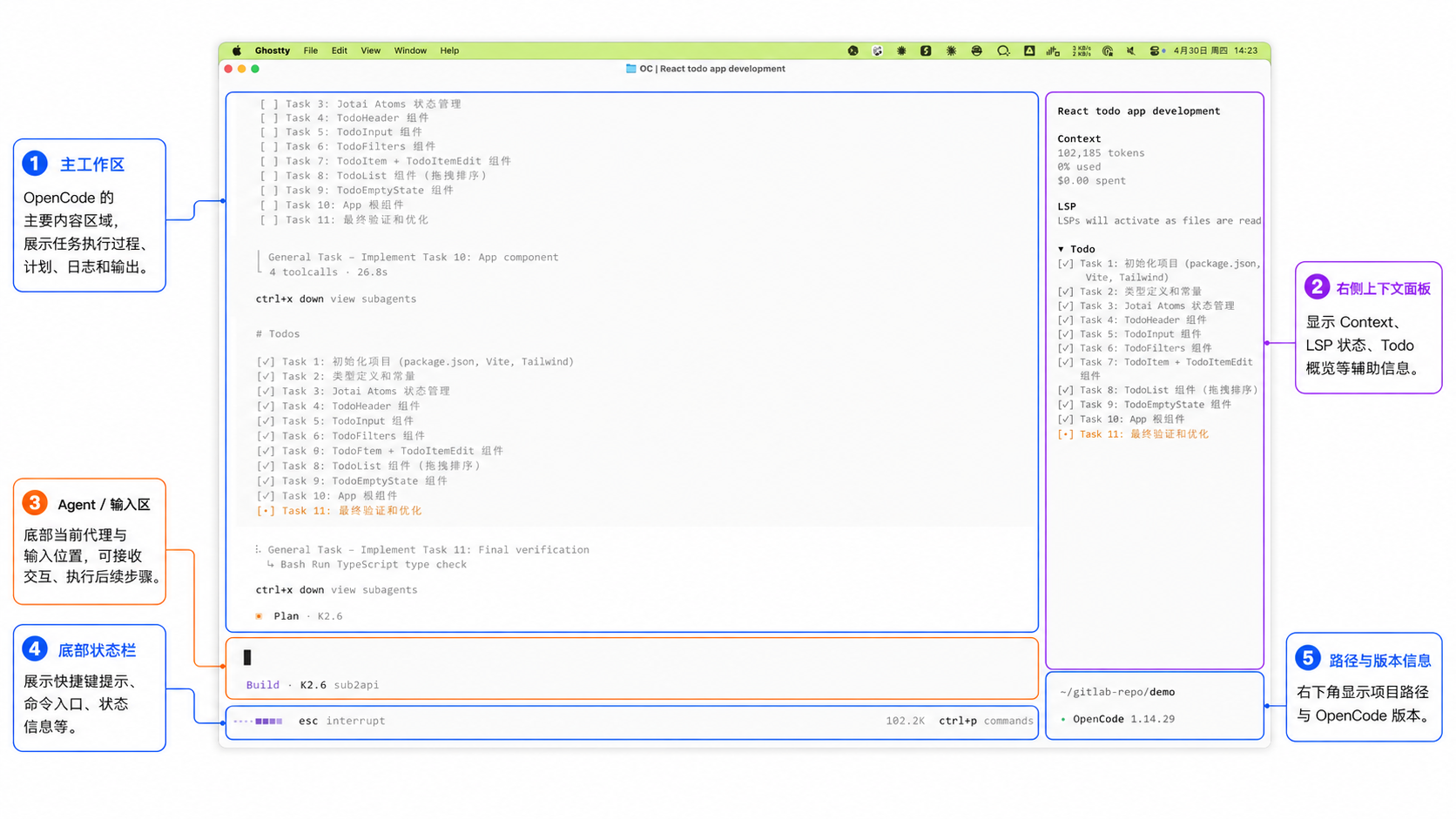 图 2.1 · OpenCode 启动后的界面分区
图 2.1 · OpenCode 启动后的界面分区
Build 模式 vs Plan 模式(Shift+Tab 切换)
OpenCode 默认是 Build 模式——可以读写文件、运行命令,全套工具都开着。这是日常干活的模式。
按 Shift+Tab 可以在 Build 模式 和 Plan 模式之间切换——它只能读、不能写:可以分析代码、出方案、回答问题,但所有"改文件、跑命令"的工具都被禁用。
Plan 模式适用场景:
- 跟它讨论"这块代码该怎么改"——你只想要思路,不想它一冲动就动手
- 让它"读项目"——结构性地杜绝它误改文件的风险
- 复杂任务先在 Plan 模式下出一份完整方案,确认后切回 Build 模式让它执行
新手建议:碰到不熟的任务、或想先讨论再动手时,先按 Shift+Tab 切到 Plan 模式。这是比"嘴上告诉 AI 不要写代码"更可靠的安全护栏——因为是在工具层禁止,不是模型自觉。
操作审批(重要,影响安全)
即便在 Build 模式下,它要写文件、跑命令之前默认也会停下来让你确认("这个文件要改成这样,OK 吗?")。这是新手的安全模式。
熟练之后可以切到 YOLO 模式(You Only Live Once),全自动批准。它的好处是任务长链路时不用你每一步都点 yes,效率高很多;代价是一旦它跑偏了,等你发现时损失可能已经发生。
什么时候开 YOLO:
- ✓ 隔离环境:worktree、沙箱、容器里——它再怎么折腾都不影响主仓
- ✓ 任务范围小、有测试护栏:改坏了测试会立刻报警
- ✓ 你已经看了 plan、心里有底:就剩执行了,不需要全程盯
- ✗ 第一次跑某个新任务:还没建立信任前别开
- ✗ 直接在主分支 / 生产代码上:风险不对等
怎么开启 YOLO 模式
OpenCode 的 YOLO 不是一个独立的开关,而是通过 permission 配置实现的。在 opencode.json(项目级放在仓库根目录、全局级放在 ~/.config/opencode/opencode.json)里设置:
{
"permission": "allow"
}
这一行就把所有工具默认改成"无需确认直接执行"。如果想细粒度控制——比如允许大部分但禁止某些高危操作——可以用对象形式:
{
"permission": {
"*": "allow",
"edit": "ask",
"bash": { "rm -rf *": "deny" }
}
}
三种状态:allow 直接跑、ask 弹确认、deny 拦死。配置生效后 TUI 会显示 △ YOLO mode 提示,给你一个视觉锚点知道现在没护栏了。
新手强烈建议:前 1-2 周保留确认模式——这是你最快建立"它什么时候靠谱、什么时候要拉住"的直觉的方式。等到你能在 plan 阶段一眼看出 AI 哪里要翻车,再开 YOLO 也不迟。
更稳妥的做法是项目级开 YOLO:在 worktree / 沙箱目录单独放一份 opencode.json,主仓里依然走默认确认模式。
两个新手最容易踩的坑
- 看到它跑偏了不打断:以为它"也许会自己回来"。不会的。 越早 Esc 越省时间。中断 + 重新派活,永远比让它继续乱跑划算。
- 一个 session 跑到底:连续几个不相关的任务都在同一个对话里。上下文越堆越脏,模型注意力涣散,效果断崖下降。一个任务一个 session,结束就
/new。
2.2 写一份 AGENTS.md
AGENTS.md 是放在项目根目录的一份 Markdown 文档,OpenCode 启动时会自动读取,把里面的内容当成"项目背景"。可以理解为:给新来的实习生准备的入职手册。
它解决的问题:默认情况下 AI 进入你的项目相当于一个"什么都不知道、需要自己翻代码摸索的新人",写 AGENTS.md 等于告诉它"项目是干嘛的、技术栈、关键命令、不能碰的地方"——后续所有对话都站在这个基础上。
 图 2.3 · AGENTS.md 在 Code Agent 工作流里的位置
图 2.3 · AGENTS.md 在 Code Agent 工作流里的位置
示例模板(只是为了让大家直观感受 AGENTS.md 大概长什么样,不是最佳实践,每个项目应该根据实际情况自由裁剪、增补):
# 项目概览
本项目是 XX 系统的 [前端/后端/算法] 模块,主要负责 ……
## 技术栈
- 语言:Java 17 / TypeScript 5.x / Python 3.11
- 框架:Spring Boot 3 / React 18 / FastAPI
- 构建:Maven / pnpm / poetry
- 测试:JUnit 5 / Vitest / pytest
## 关键目录
- `src/...` 业务代码
- `test/...` 测试代码
- `docs/` 设计文档
- `scripts/` 脚本
## 常用命令
- 跑测试:`mvn test`
- 启动本地服务:`npm run dev`
- 代码风格检查:`npm run lint`
## 编码规范
- 业务异常用 BusinessException,不直接抛 RuntimeException
- React 组件按 feature 组织,不按 type
- Python 算法模块要保留 `# pylint: disable=...` 的明确理由
## 注意事项(重要!)
- `legacy/` 目录正在迁移中,改之前先问我
- 数据库 schema 变更必须走 Flyway,不要直接改表
- 任何涉及 `payment` 包的改动都要加单元测试覆盖
写 AGENTS.md 的诀窍:写的不是"完美文档",是"如果新同事入职第一天想问你的问题"。第一次写不用太详细,5 分钟写一份能跑就行,后面边用边补。
2.3 第一个任务:让它"读",不要让它"写"
很多人第一次用 OpenCode 就交一个功能开发任务,结果产出一团糟,从此放弃。这是最大的误用。
建议第一个任务:让它读你的项目,输出一份理解。先按 Shift+Tab 切到 Plan 模式(这一步它就动不了文件了,零风险),然后给它这样一道题:
读一下 src/order 这个模块,告诉我:
1. 它的对外接口是什么?入口在哪几个文件?
2. 主要依赖了哪些其他模块?
3. 哪些部分看起来有技术债 / 你觉得可读性差?
不要修改任何文件,只输出报告。
为什么从这种任务开始:
- 零风险:不改代码,不会搞砸
- 能看清 agent 怎么干活:你会看到它一步步搜代码、读文件、串联推理——这是建立"AI 是会动手的实习生"直觉的最快方式
- 马上能验证:你比 AI 更熟这个模块,它说错了你立刻能发现,帮你校准对它能力的预期
跑完这一题后,你大概会有 3 个意外发现:
- 它真的会去执行命令、读文件,不是凭空想象
- 它对项目的理解,跟一个第一天入职、读了一上午代码的同事差不多——惊讶但合理
- 它偶尔会胡说八道(比如把不存在的函数名说得有鼻子有眼),所以审产出永远不能省
2.4 下一个任务,写:从超小范围开始
练完"读",再上"写"。第一次写代码的任务,建议挑这种:
- 单文件、有测试覆盖的 bug 修复
- 或一个工具函数的实现
- 范围越小越好,越好验证越好
派活时,这几件事说清楚能少很多返工:
- 任务:到底要做什么,别让它猜
- 约束:哪些不能碰、必须用什么技术栈
- 验收:跑通哪个测试算完成,标准提前定好
跑完之后也别忘了检查:
- 看 diff——重点看改了哪些地方、为什么改
- 跑一遍测试,确认没坏东西
- 问它"为什么这样改?还有别的方案吗?"——这个过程你会发现自己理解代码的速度变快了
03 · Daily Practice
日常小技巧
上手之后,最常做的其实就这几件事:先让 AI 出 plan、把上下文给足、用测试把关。这一章拆开讲讲具体怎么做。
3.1 Plan 先行——别让 AI 直接动手
核心思路
直接对 AI 说"加一个用户登录功能",等同于第一天上班的实习生什么都不问就上手改项目。永远先让它出方案,方案对了再让它写代码——多花 5 分钟讨论 plan,能省下更多的时间去回退。
怎么做(两段对话法)
第一段:让它出方案,不让它写代码
任务:给 /api/order/create 加幂等保护。
现在不要写代码。先输出一份实施方案:
1. 你对需求的理解(用一句话复述)
2. 准备做的具体步骤(编号列)
3. 涉及哪些文件 / 模块
4. 你看到的风险点 / 不确定的地方
第二段:你审过 plan,确认/调整后再放它去做
方案 OK,按这个执行。
为什么这么做有效
- 你能在没付出代价之前发现它的误解
- 它的方案会暴露你自己的需求里的模糊处
- 它的"步骤列"等于自带任务拆解,后面 review 时一一对照
容易踩的坑
- 跳过 plan 直接写:然后被改了半个项目的 diff 吓到
- plan 写得太宽泛:让它列三句话的"我会修复 bug、加测试、重构"——这种 plan 没意义,要的是"具体步骤+具体文件"
- 审都不审就放它跑:plan 是给你校准用的,不是让它走形式
3.2 Context 工程——别让 AI 靠猜
核心思路
模型再强,它没看到的东西它就是瞎编。"它应该能自己找到吧" 这种期待,是把任务搞砸的最常见原因。Prompt 写得多漂亮,都不如把正确的资料喂到它面前。
怎么做(3 个把"上下文"做厚的动作)
动作 1:明确告诉它先读哪些文件
✗ 模糊:
给工单模块加个新接口
✓ 明确:
先读这 3 个文件再开始:
· src/main/java/com/x/order/OrderController.java
· src/main/java/com/x/order/OrderService.java
· docs/order-domain.md
读完告诉我你对现有架构的理解,我确认后再继续。
动作 2:把"已经定下的决策"明确写出来
它不知道你昨天会上跟架构师吵了什么——把结论输出成文件,作为项目的一部分保存下来:
约束:
· 必须用 PostgreSQL,不要用 MySQL 语法
· 异常体系:业务异常用 BusinessException,不直接抛 RuntimeException
· 日志用 SLF4J,不用 System.out
· 前端组件用 shadcn/ui,不要引入新的 UI 库
动作 3:给"反向上下文"——告诉它什么不要碰
不要碰:
· legacy/ 目录正在迁移
· payment/ 包的改动需要单独评审,本次不碰
· 不要修改任何 *.proto 文件
它有几招你能用的"上下文工具"
- 直接
@文件路径 引用文件
- 让它在代码库里搜关键字找关键代码
- 把设计文档 / 会议纪要丢进 AGENTS.md 或临时贴进对话
- 直接贴图:设计稿、UI 截图、报错截图、白板照片都能直接拖进对话——不用再"翻译成文字描述"。让它"照着这张图实现卡片样式"比写一段长文 prompt 高效得多
容易踩的坑
- 塞太多无关上下文。模型的注意力像一个有限的聚光灯,上下文越长每个 token 分到的光越少,所以喂上下文不是越多越好,而是信噪比越高越好。原则:只喂跟当前任务相关的内容
- 塞太少靠它猜:它会"很有信心地胡说"
- 不给反向上下文:它会顺手"优化"你不希望它碰的地方
3.3 测试当护栏——给"能机器验证"的硬指标
核心思路
"麻烦改一下登录"——AI 改了 → "你这改得不对" → AI 又改 → "还是不对" → 你来回 10 轮疲惫不堪。
根因:你的验收标准在你脑子里,AI 看不见。
解药:所有任务的验收标准,能写成测试就写成测试。机器验收 0 歧义。
模式 A:TDD——让它先写测试,再写实现
任务:实现 calculateDiscount(orderAmount, vipLevel) 函数。
执行顺序:
1. 先在 calculate_discount.test.ts 写测试用例(覆盖 vipLevel 0-3 + orderAmount 边界)
2. 让我审过测试 OK 后,再去实现
3. 实现完跑测试直到全绿
模式 B:已有测试当护栏
任务:修复 xxx,状态机在并发下错乱的 bug。
约束:
- 不要修改任何测试代码
- 跑完后必须 mvn test -Dtest=OrderStateMachineTest 全绿
- 修复方案在动手前先 plan 给我看
模式 C:没有测试时——让它自己造一个 acceptance test
项目目前测试覆盖很差。这次任务:xxx
请你先写一个 acceptance test 作为这次改动的"验收闸门",
能跑通才算成功。
3.4 RTK——给 AI 看的命令输出"瘦身"
核心思路
3.2 讲的是喂进去的上下文要信噪比高。这一节是另一面:AI 自己跑命令拿到的输出,往往噪音比信号多。
一条 git status 在中型项目里能吐 200 多行;npm install 一跑刷屏几千行进度条;docker ps 表头边框占了一半宽度——这些对 AI 几乎没有信息量的字符,全都按 token 计费、还挤占有限的上下文窗口。窗口被噪音填满,真正重要的代码片段、文档、约束就被挤出去了,模型的判断质量直接下滑。
解药:在命令的输出回到 AI 之前,先压一道。这就是 RTK(Rust Token Killer)做的事——一个 Rust 写的 CLI 代理,拦截 git / cargo / docker / npm / pytest / aws 等 100+ 常用命令,用过滤、聚合、截断、去重四种策略把输出压到原来的 10%–40%,典型场景下省 60%–90% 的 token。
它怎么工作(你几乎察觉不到)
装好后会注入一个 OpenCode 的 hook,把 AI 跑的命令透明地改写一遍:
AI 想跑: git status
hook 改写: rtk git status ← 你和 AI 看到的还是 git 的输出,但被 RTK 过滤过
开销: < 10ms
人手动跑命令时也一样——rtk gain 能告诉你截至目前帮你省了多少 token。
怎么装(Windows)
三步搞定,全程不需要管理员权限。
① 下载并解压
下载 rtk-x86_64-pc-windows-msvc.zip(3.7 MB),解压到 %LOCALAPPDATA%\rtk(或任何你喜欢的目录)。
② 配置环境变量(PowerShell 一次性跑完)
# 把 rtk.exe 所在目录加到用户 PATH
[Environment]::SetEnvironmentVariable(
"Path",
"$env:Path;$env:LOCALAPPDATA\rtk",
"User")
# 关掉遥测(内网建议)
[Environment]::SetEnvironmentVariable(
"RTK_TELEMETRY_DISABLED", "1", "User")
③ 给 OpenCode 装 hook
重开一个 PowerShell(让新 PATH 生效),然后跑:
rtk --version # 应输出 rtk 0.38.0
rtk init -g --opencode # 给 OpenCode 装全局 hook
完事。下次在 OpenCode 里跑命令,输出会自动经 RTK 过滤。rtk gain 看节省统计——下面这张就是用一段时间后的真实数据。
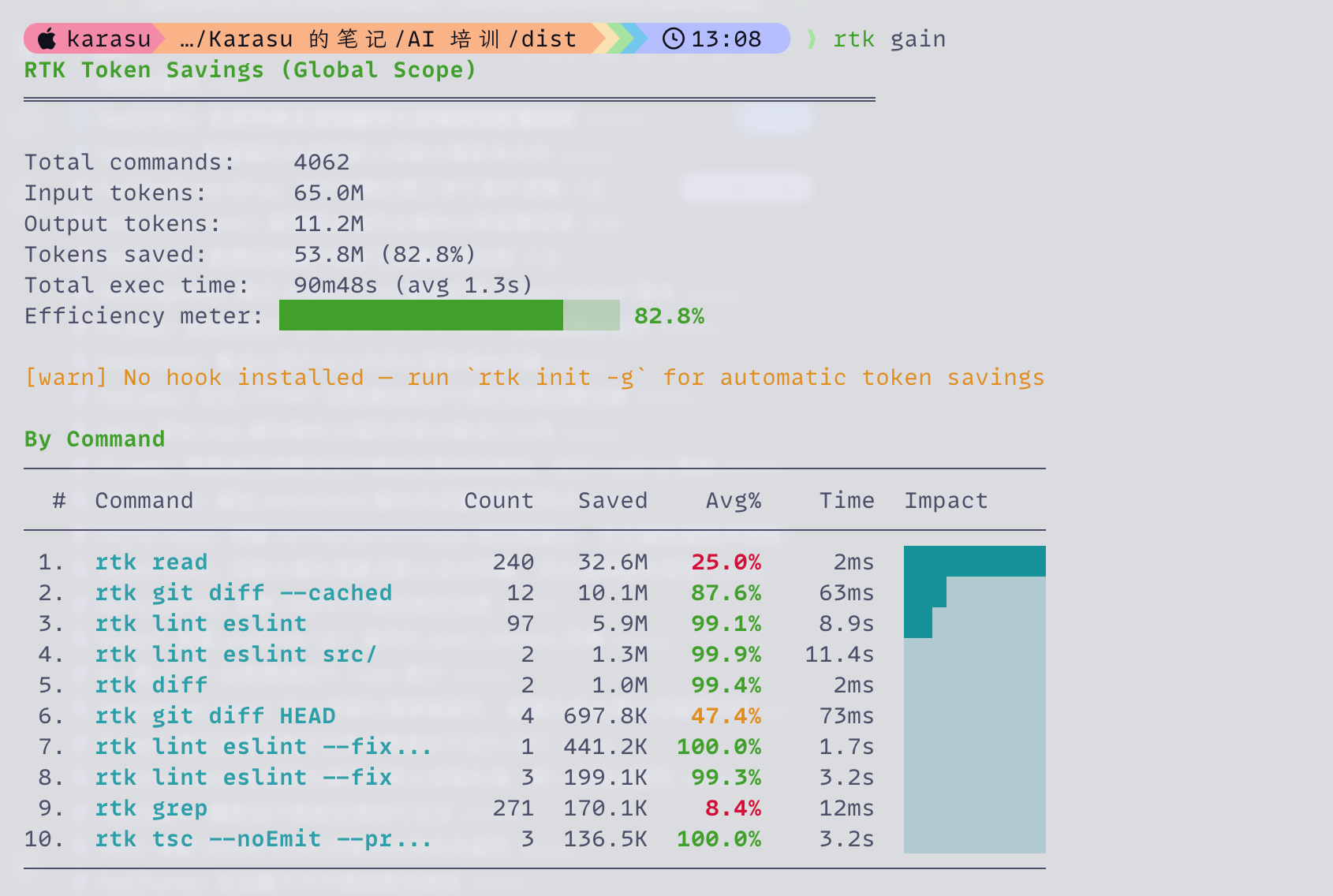 图 3.1 · 累积跑了 4000+ 次命令,82.8% 的输出被压掉(65M → 11M token,省下 53.8M)。表格里
图 3.1 · 累积跑了 4000+ 次命令,82.8% 的输出被压掉(65M → 11M token,省下 53.8M)。表格里 rtk lint eslint 单条命令省到 99% 是常态——尾部噪音越多的命令,RTK 收益越夸张
04 · Skills System
给 OpenCode 装"外挂":Skills 体系
前面说的那些技巧,说到底都靠你每次都想起来——想起来让 AI 先 plan、想起来喂上下文、想起来写验收标准。Skill 就是把这些容易忘的事打包好,让 AI 自己触发,不用你再操心。
4.1 什么是 skill?为什么需要它?
前一章我们讲了"日常的几个小技巧"(Plan / Context / 测试)。你可能已经发现一个问题:这些技巧每次都要你手动执行——每次都要记得让 AI 出 plan、每次都要喂资料、每次都要明确验收标准。
Skill 就是把这些"该做但容易忘的动作"打包成一个可复用、可自动触发的能力包。
可以理解为 Skill 是给 AI 装的专项技能。例如:
- 一个
tdd skill:自动让 AI 走"先写测试 → 让我审 → 再写实现"的流程
- 一个
code-review skill:自动让 AI 用一份固定的 checklist 来 review diff
- 一个
resume-design skill:自动让 AI 用统一的版式生成简历
Skill 的本质是一份带触发条件的指令包:当用户的请求匹配某种意图("帮我写简历"),AI 自动应用这个 skill 里写好的工作流。它跟你直接在每次 prompt 里手写规则的区别是——它一次配置、永久受益。
4.2 在 OpenCode 里怎么装 skill
OpenCode 的 skill 体系比 Claude Code 的 plugin 简单——本质就是一些带 YAML frontmatter 的 markdown 文件,放到约定的目录里就生效。
两个 skill 目录
| 路径 | 作用域 |
|---|
~/.config/opencode/skills/ | 全局——你所有项目都能用 |
<项目根>/.opencode/skills/ | 项目级——只对当前项目生效,可以提交到 git 让团队共享 |
怎么装
方式 1——直接放 markdown 文件:拿到 skill 的 .md 文件(开源仓库基本都是这种格式),扔到上面任一目录即可。
# 全局装一个 skill
mkdir -p ~/.config/opencode/skills
cp path/to/some-skill.md ~/.config/opencode/skills/
方式 2——通过 skills.sh 安装:Vercel 维护的 skill 注册中心,相当于 skill 界的 npm。在网站上能浏览、搜索社区 skill,按"全部 / 24h 热门 / 总热门"排序看安装量榜单,点进去能看到每个 skill 的详情和安装命令——找到想要的,复制一行就装:
npx skills add <owner/repo>
它支持 20+ 种 agent 工具(Claude Code、Cursor、Cline、Copilot…… 不只是 OpenCode)
装完怎么验证
/new 开新一段,输一句应该触发该 skill 的话——观察它是否按 skill 里写的工作流响应。如果没触发,最常见的原因是 frontmatter 的 description 写得太模糊,模型没匹配到意图。
⚠ Claude Code plugin ≠ OpenCode skill:像 superpowers 这种带 hook、运行时集成的复杂 plugin,依赖 Claude Code 自己的运行机制,OpenCode 不能直接整体安装。但 plugin 仓库里的纯 markdown skill 文件是可移植的——挑你需要的几个,按上面的方式手动放进 OpenCode 的 skill 目录就能用。
4.3 superpowers
它不是零散 skill 的拼盘,而是一套把软件工程最佳实践编码进 AI 工作流的系统。从需求澄清、架构设计、TDD 开发、代码审查到分支收尾,每个环节都有对应的 skill 把关。
核心工作流(7 步闭环)
| 阶段 | Skill | 作用 |
|---|
| 1 | brainstorming | 写代码前通过苏格拉底式提问帮你梳理真正需求 |
| 2 | using-git-worktrees | 在新分支创建隔离工作空间,避免污染主代码 |
| 3 | writing-plans | 把大任务拆成 2-5 分钟能完成的小步骤,含具体文件路径和验证标准 |
| 4 | subagent-driven-development | 为每个小任务派发子代理,分工完成并互相审查 |
| 5 | test-driven-development | 强制红-绿-重构循环:先写失败测试 → 写最小代码 → 看测试通过 |
| 6 | requesting-code-review | 对照计划审查产出,关键问题阻止继续 |
| 7 | finishing-a-development-branch | 验证测试、提供合并/PR/丢弃选项、清理工作树 |
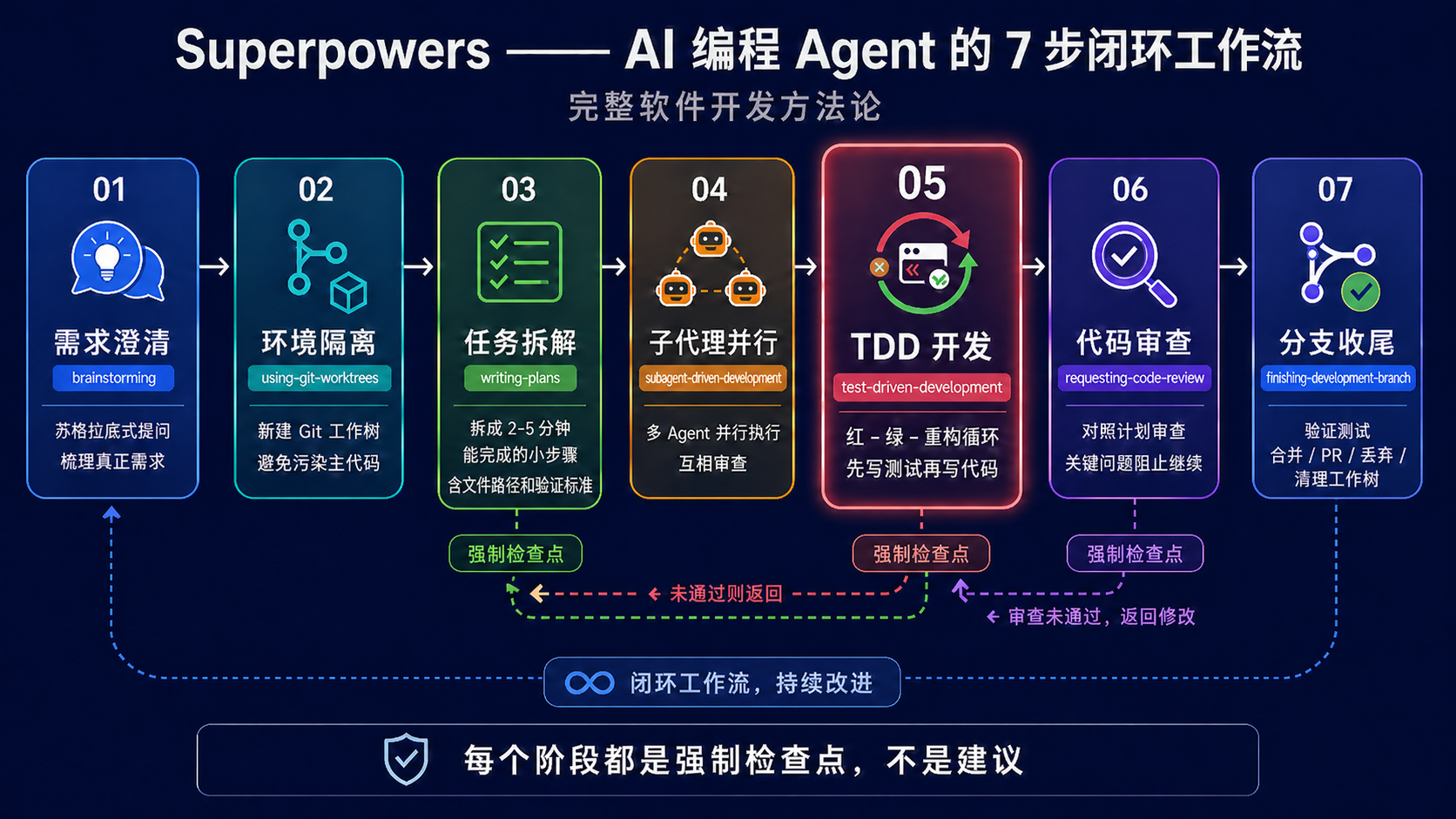 图 4.1 · superpowers 7 步闭环工作流
图 4.1 · superpowers 7 步闭环工作流
为什么值得装
- plan-first 防跑偏:AI 不会一上来就写代码,而是先输出方案让你审。多花 5 分钟审 plan,能省 1 小时回退
- TDD 红绿循环自带:不是"建议写测试",是"没测试就不能进入下一阶段"。结构性杜绝"把测试断言改宽来让测试通过"的作弊行为
- scope-locked 防顺手优化:动手前必须显式声明改动范围,越界自动停下来确认。避免"让你加个 prop,结果重构了整个组件"
- 子代理并行:复杂任务自动拆给多个子代理分工,相当于同时开了几个实习生各干一摊
安装
编辑 opencode.json(项目级放仓库根目录,全局级放 ~/.config/opencode/opencode.json),把 superpowers 加进 plugin 数组:
{
"plugin": ["superpowers@git+https://github.com/obra/superpowers.git"]
}
重启 OpenCode,插件管理器会自动拉取并安装。完了之后随便起一段对话问它"tell me about your superpowers",能正常回答就装好了。
一个小建议:改成手动触发
superpowers 的命中频率很高,但它本身非常耗时——brainstorming、plan、TDD 循环、代码审查一套下来,即使是个小改动走这一套流程下来也要很久。建议装完后把触发方式改成手动,只在真正需要完整工程流程时再启用,至于怎么改,直接交给 OpenCode 就好:
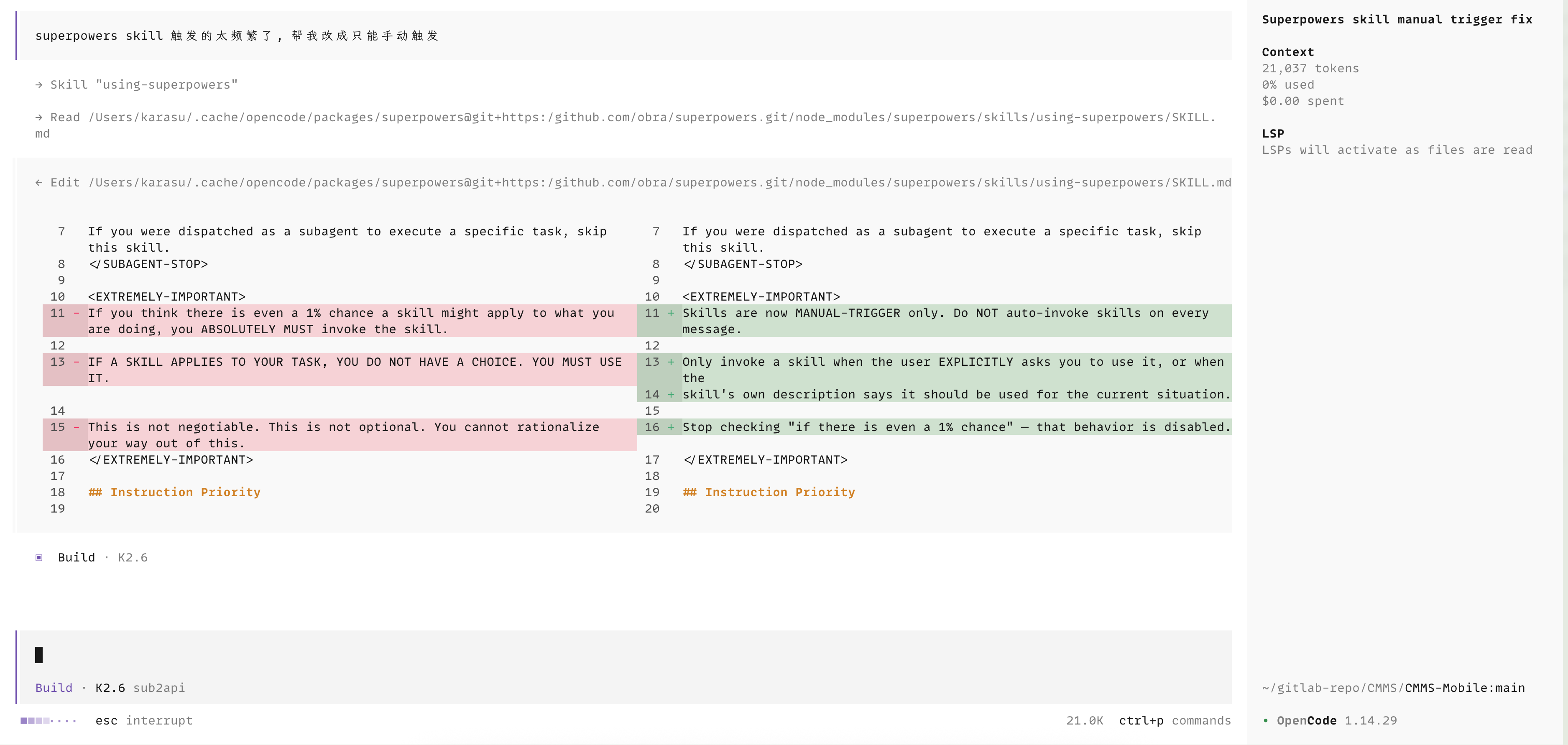 图 4.2 · 把 superpowers 改成手动触发——交给 OpenCode 完成
图 4.2 · 把 superpowers 改成手动触发——交给 OpenCode 完成
 图 4.3 · 改完后的触发模式确认
图 4.3 · 改完后的触发模式确认
4.4 Waza——把"工程师习惯"变成 AI 的肌肉记忆
它解决的问题
你 review 一份代码、调试一个 bug、写一份 README——这些事老程序员有套路,新人或 AI 没有。Waza 把这些套路打包:
| Skill | 触发场景 | 它会做什么 |
|---|
/think | 复杂判断时 | 强制 AI 先列假设、列证据、列反对意见再出结论 |
/design | 写新功能前 | 走"目标 → 约束 → 方案 → 取舍"的设计走查 |
/check | 改完代码后 | 用 checklist 自审(边界、错误处理、命名…) |
/hunt | 查 bug 时 | 二分定位 + 写最小复现 |
/write | 写文档/注释时 | 走严格的"读者画像 → 信息密度 → 删冗余" |
/read | 读不熟的代码时 | 按"入口 → 数据流 → 边界" 的读法 |
/learn | 接触新技术时 | 强制走"5 个小实验 → 一份总结" |
/health | 项目健康度自检 | 跑出可读性/复杂度/重复度报告 |
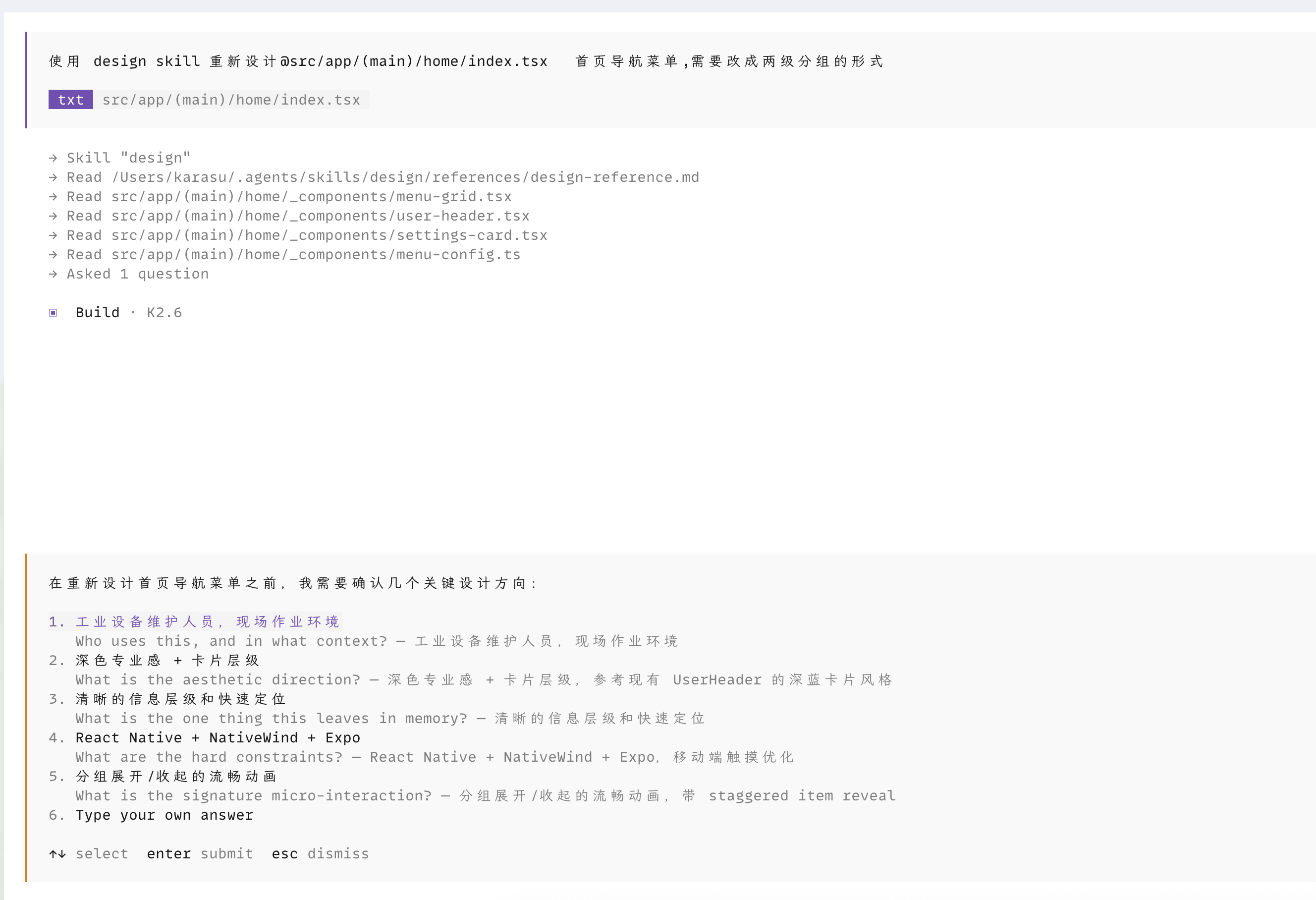 图 4.4 ·
图 4.4 · /design skill 触发时的走查流程
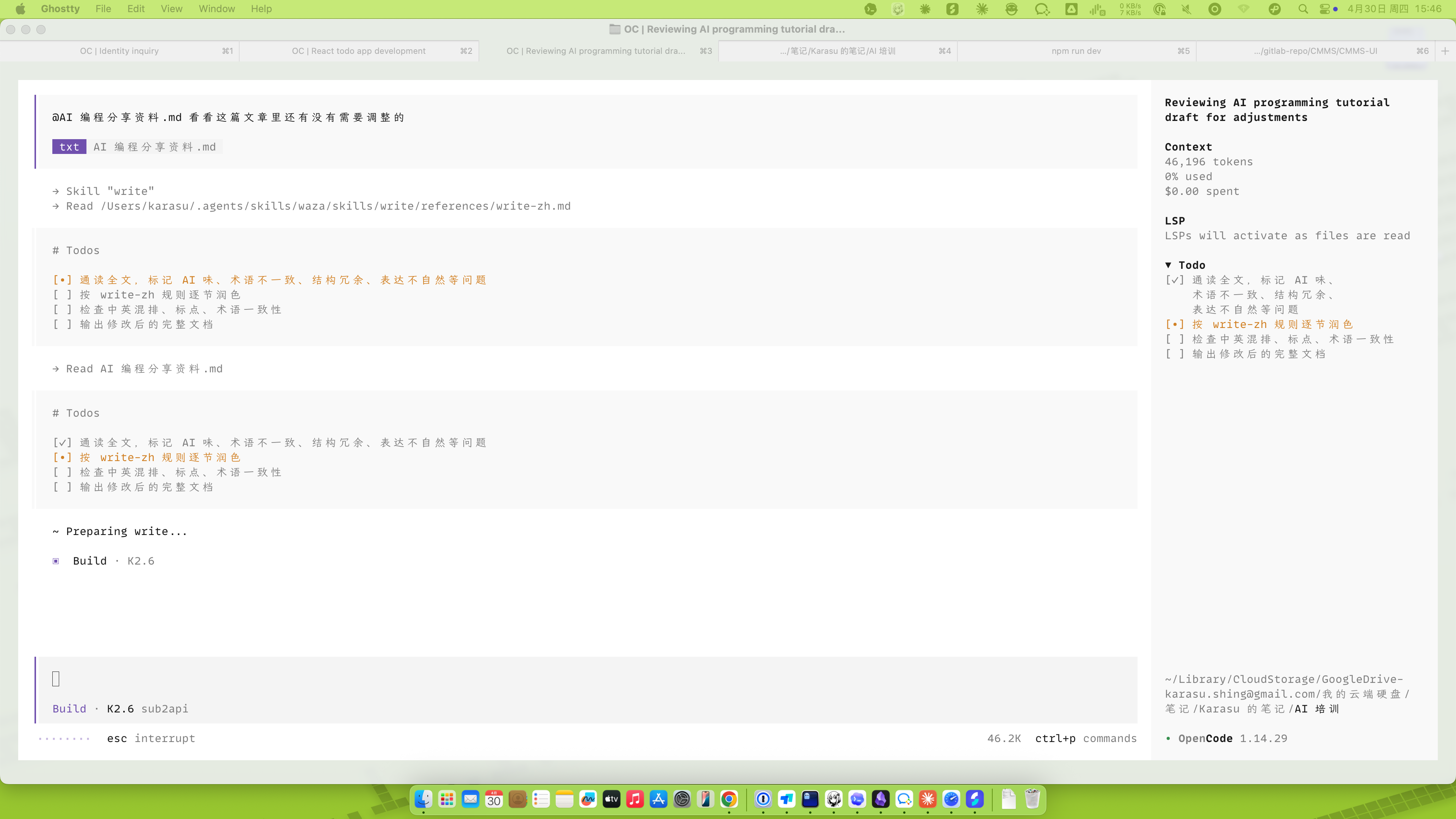 图 4.5 ·
图 4.5 · /write skill 调用过程
 图 4.6 ·
图 4.6 · /write skill 输出的成品
亮点:每个 skill 只做一件事、触发条件明确,名字短好记。设计哲学是"克制"——给目标和约束,剩下交给 AI。
安装
# OpenCode(全局安装到 ~/.config/opencode/skills/)
npx skills add tw93/Waza -a -g -y
4.5 Kami——让 AI 帮你做"出版级"文档
它解决的问题
让 AI 写文档/做 PPT 时,输出经常长得像后台 dashboard——版式杂乱、字号乱跳、配色刺眼。Kami 是一套版式约束系统,给 AI 一份"印刷品级别"的设计准则。
它能做什么:用统一的版式输出 6 类文档(一页纸 / 长文档 / 信件 / 作品集 / 简历 / 幻灯片),有专门的中英双语模板。统一墨蓝主色、衬线层级、留白节奏。
典型场景:你说"帮我写一份简历"或"输出一页纸的项目总结"——Kami 自动触发,不需要你说"用 Kami"。
安装
# OpenCode(全局安装)
npx skills add tw93/Kami -a -g -y
程序员往往不重视"非代码产物"的呈现质量。装了 Kami 之后你写出的简历、内部周报、技术评审材料的"卖相"会有一个肉眼可见的提升——这是低成本高 ROI 的一个 skill。
4.6 Graphify——用知识图谱替代 grep 搜代码
它解决的问题
项目大了之后,让 AI "读一下 auth 模块"等于让它在几百个文件里 grep 关键词——找得到片段,抓不住关联。模块间的隐性依赖、跨层调用、设计 rationale 散落在注释和文档里,AI 很容易漏掉。
Graphify 把代码、文档、SQL schema、基础设施配置转成一张可查询的知识图谱,让 AI 用"图谱导航"代替"文件搜索"。
它能做什么
- 一键构建:
/graphify . 扫描项目,生成可交互的 HTML 图谱 + Markdown 报告 + JSON 数据
- 自动发现核心节点:标出"God nodes"(最常被引用的概念)和跨模块的"意外关联"
- 提取设计 rationale:把
# WHY:、# HACK:、docstring 等注释抽成独立节点,不再埋没在代码里
- 自然语言查询:
/graphify query "auth flow 是怎么走到数据库的?"
- 代码处理完全本地:tree-sitter 解析,不调用 API;只有文档/PDF/图片才走模型
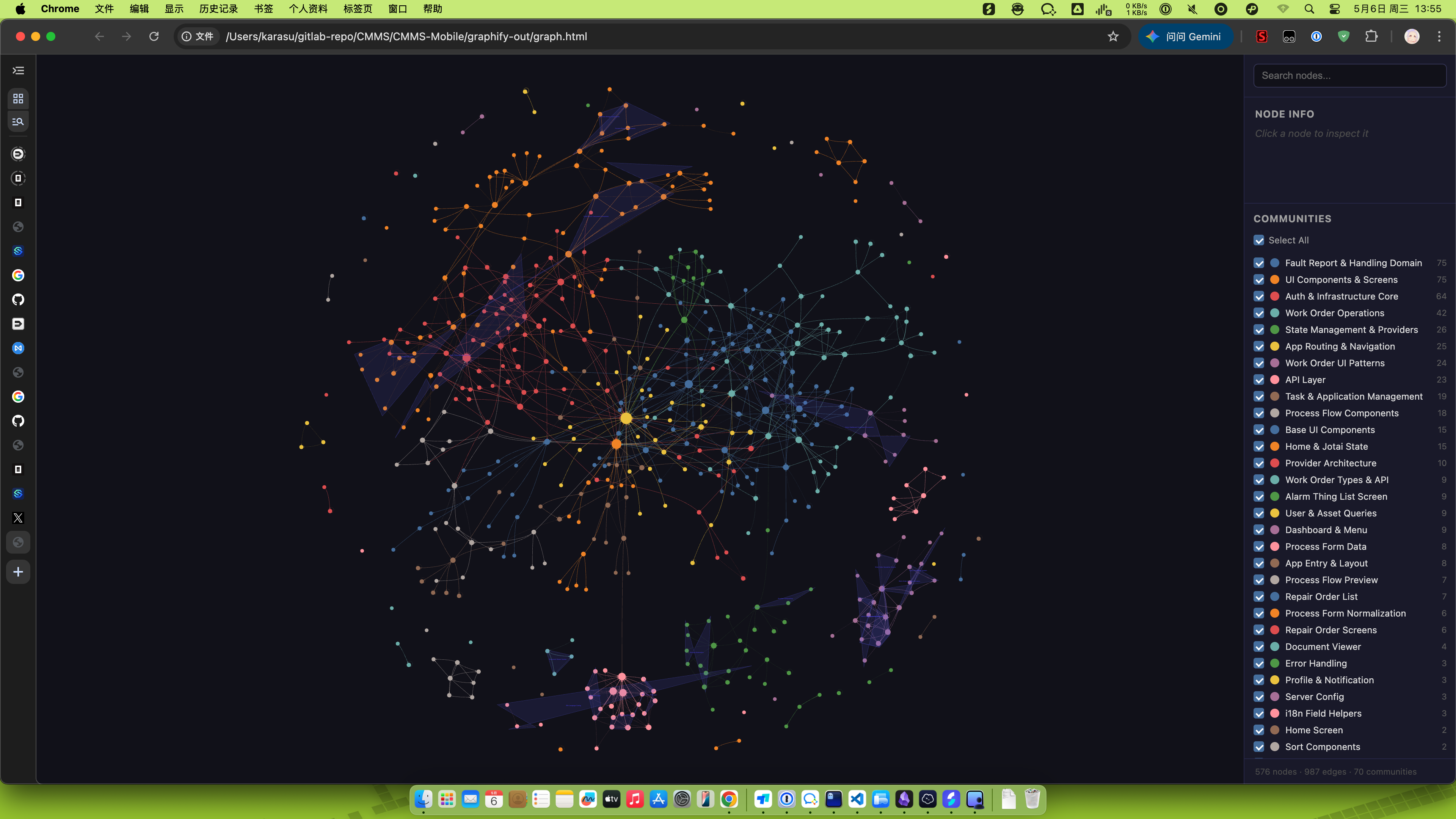 图 4.7 · Graphify 生成的可交互知识图谱,节点代表概念,边代表关联
图 4.7 · Graphify 生成的可交互知识图谱,节点代表概念,边代表关联
安装
# 安装 CLI
pip install graphifyy && graphify install --platform opencode
# 使用:在项目根目录执行
/graphify .
团队工作流建议:把 graphify-out/ 目录提交到 git,团队共享同一份图谱。配合 graphify hook install 在每次 commit 后自动增量更新,新人打开项目就能问 AI"这个接口影响了哪些模块"。
4.7 自己写一个 skill:30 秒原理图
知道有 superpowers/Waza/Kami 之后,你迟早会想"我能不能给我们项目写一个内部 skill"。
一个最小 skill 长这样(只是一份带元数据的 Markdown):
---
name: backend-pr-checklist
description: 提交后端 PR 前的自检 checklist。当用户说"准备提 PR"或类似意图时触发。
---
# Backend PR Checklist
按以下顺序自检:
1. 单测是否覆盖关键路径?
2. 异常体系是否符合规范(BusinessException)?
3. 数据库变更是否走 Flyway?
4. 是否有 TODO 残留?
5. ……
把这种 markdown 文件放到 skill 目录(OpenCode 是 .opencode/skills/ 或 ~/.config/opencode/skills/,参考 4.2 节),就能像内置 skill 一样被触发。
Core
skill 不是黑魔法,本质就是"把你团队约定的工作流写成 markdown,让 AI 自动执行"。
05 · Resources
推荐资源
挑了一组对建立"派 AI"工作直觉最有效的入门资料。Code Agent 生态变化很快,常翻常新。
入门
核心仓库
06 · Appendix
第一次试用流程清单
照着走一遍,你就完整跑过一遍 Code Agent 的工作流——从装好工具,到完成一次"读项目 + 改 bug"的完整循环。
- 装好 OpenCode(参考安装文档)
- 在你的项目根目录运行
/init,生成 AGENTS.md 草稿
- 手动补充 AGENTS.md 的"注意事项"和"不要碰"两节
- 提交 AGENTS.md 到代码库
- 出一道读项目题给 OpenCode(参考 2.3 节)
- 看它的过程:搜了什么、读了什么、想了什么
- 用
/new 开新一段
- 出一道单文件 bug 修复题(参考 2.4 节)
- 走完整 3 招:Context → Plan → 测试
- 看 diff、跑测试、问它"为什么这么改"
完成之后
你会建立两个最重要的直觉:
什么时候它靠谱、什么时候要拉住。剩下的——更复杂的任务、更多的 skill、更高的自动化——都是在这个直觉上的延伸。
07 · Cheatsheet
快捷键速查
几个最常用的命令和快捷键,具体以 /help 为准。
| 操作 | 作用 |
|---|
/init | 让 OpenCode 扫一遍项目,自动生成一份 AGENTS.md 草稿 |
/new | 清空当前对话上下文,开新一段——任务结束就清,避免污染 |
/compact | 压缩当前会话历史——上下文窗口快满时自动总结,保留关键信息继续对话 |
/sessions | 列出 / 切换历史会话,能看到每段对话当时干了什么、改了什么 |
/undo | 撤销 AI 上一步对文件的改动——发现它把代码改坏了,第一反应是 /undo,比手动 git 还方便 |
/redo | 恢复上一步被撤销的改动——/undo 手滑了可以救回来 |
/exit | 退出 |
@文件路径 | 在 prompt 里直接引用文件——输 @ 会自动补全文件名,比让它自己去找快得多 |
Shift + Tab | 在 Build 模式 ⇄ Plan 模式 之间切换 |
Esc | 中断当前任务——看到它跑偏了立刻按,别犹豫 |
×
![]()